WordCal - A Python Script
What is the WordCal Python Script?
It is a python script which counts the number of times a particular character appears in a file. As shown by the below image the script provides the percentage that a character appears.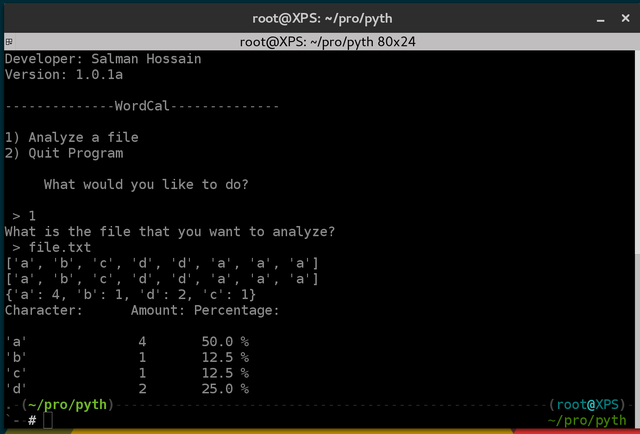
How to use the WordCal Script?
Using the wordcal script is relatively simple.
1) Install the wordcal.py file from GitHub.
2) Enter your favorite terminal.
3) Enter the following...
$ python wordcal.py
This should lead you to the following prompt...
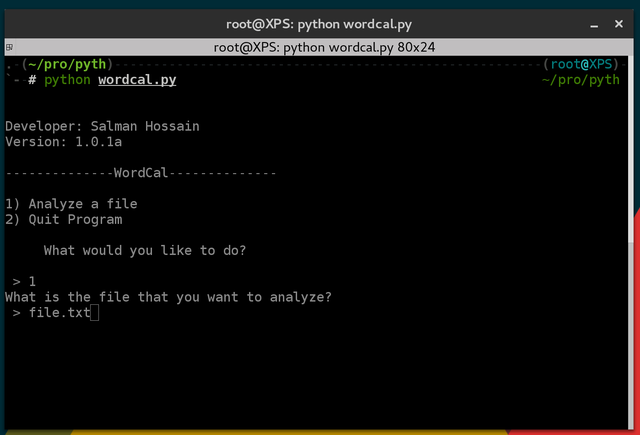
Once prompted you are given two options at the start. The two options are as follows...
1) Analyze a file
2) Quit Program
To select an option enter 1 or 2.
Entering 1 brings you to the next prompt asking for the filename.
Entering 2 exits the program returning you to the terminal without doing anything.
After pressing 1 enter the name of the file you want to analyze.
Enter the full file name including any extensions that the file may have.
For example if you wanted to use the script on a file called "file.txt" ...
> file.txt
How does the WordCal Python Script work?
The script runs from the terminal and asks for a filename. Entering the filename will access the file and turn the contents of the file into an array. Several functions in the program will sort out the contents of the file. Eventually returning the amount of times a character appears and the percentage.
Functions used in the script:
convertFileto_Array(filename)
This function takes an open file in read mode and turns the contents into an array. Each line of the file is an element in the array.
For example if this was a text file called file.txt ...
This is the first line This is the second line
You can use convertFileto_Array() to convert a file into an array by ...
from wordcal import convertFileto_Array
filename = open('file.txt', 'r') myarray = convertFileto_Array(filename)
print(myarray) filename.close()
Note: You can open the file in 'w+' mode as well since it doesn't trancuate the file. However opening in 'w' will produce an empty array since opening a file in 'w' in python will trancuate the file first and won't preserve the file. When importing do not add the .py extension or it won't import and make sure that the wordcal.p is within the same directory.
Now running the new code would result in a output to the terminal as such ...
['This is the first line', 'This is the second line']
Notice that this is the whole line which may be what your looking for. However if you want single characters you would have to use sorting_algorithm().
What the sorting_algorithm() function does is it adds an character from an element to an array. So all you would have to do is place myarray into the function and change the print argument so it prints the newarray ...
from wordcal import convertFileto_Array from wordcal import sorting_algorithm
filename = open('file.txt', 'r') myarray = convertFileto_Array(filename) newarray = sorting_algorithm(myarray)
print(newarray) filename.close()
Note: You can do from wordcal import * which will import all the functions. However this is generally discouraged and is considered bad practice specially with larger modules that you may import.
You should have gotten an array with a lot of elements such as the following ...
['T', 'h', 'i', 's', ' ', 'i', 's', ' ', 't', 'h', 'e', ' ', 'f', 'i', 'r', 's', 't', ' ', 'l', 'i', 'n', 'e', 'T', 'h', 'i', 's', ' ', 'i', 's', ' ', 't', 'h', 'e', ' ', 's', 'e', 'c', 'o', 'n', 'd', ' ', 'l', 'i', 'n', 'e']
Now we have each character in the array. We now make a dict using noduplicate() passing the function the new array as an argument. Now we can use noduplicate() to print the data of the noduparray returned by noduplicate().
from wordcal import convertFileto_Array from wordcal import sorting_algorithm from wordcal import noduplicate from wordcal import analyze_data
filename = open('file.txt', 'r') myarray = convertFileto_Array(filename) newarray = sorting_algorithm(myarray) noduparray = noduplicate(newarray)
analyze_data(noduparray)
filename.close()
Note: That the analyze_data() is not actually analyzing the data but really formating the data so that it is easy to read and prints.
That should produce sometime similar to the top image displaying the percentage of each character.